具体
ASCII
使用8bit表示一个字符,一共定义128个字符,其中33个是无法显示的控制字符(0-31和127的DEL),剩余是常用符号、数字、英文字母;因为仅定义128个字符,ASCII编码每个字节的最高位都是0
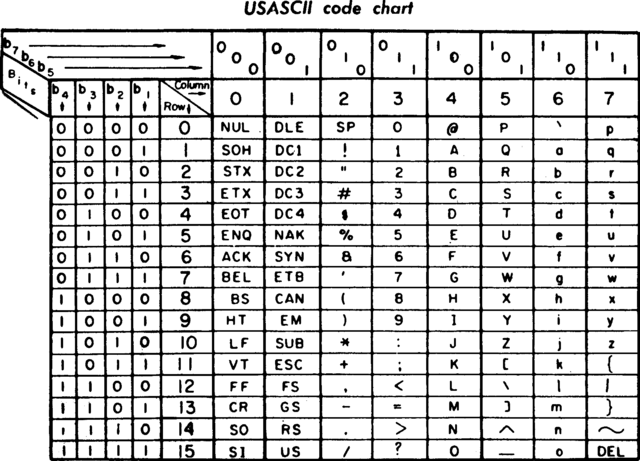
英语使用128个字符足够,其他欧洲语言会超出,额外的字母使用余下的128个字符,256个字符足够欧洲各语言编码,但问题是同一编码在不同语言中表示不同字母
GB2312
其他地区语言,例如简体中文字符远超256,使用多个字节编码一个字符,例如GB2312使用两个字节编码一个字符
GB2312共收录6763个汉字,分为一级汉字3755个,二级汉字3008个,还收录拉丁字母、希腊字母等其他682个字符;GB2312将收录的汉字进行分区,每个分区94个字符
- 01–09区为特殊符号
- 16–55区为一级汉字,按拼音排序
- 56–87区为二级汉字,按部首/笔画排序
- 10–15区及88–94区未有编码
编码时
- 第一个字节称为高位字节,记录分区,使用0xA1–0xF7(把01–87区的区号加上0xA0)
- 第二个字节称为低位字节,记录分区内排列,使用0xA1–0xFE(把01–94加上0xA0)
例如汉字’啊’排在一级汉字的第一个,即16区第一个汉字,高位字节为16 + 0xA0 = 0xB0,低位字节为1 + 0xA0 = 0xA1,以0xB0A1存储
繁体中文常用Big5编码,使用2个字节编码一个字符
Unicode
Unicode希望以一套编码完成对所有文字的编码,2016年发布的版本9.0.0收录了超过十万个字符;Unicode通过分区定义字符,分区称为平面(Plane),每个平面65536(2^16)个码点(code point),当前已使用17个平面(2^5),对应U+0000到U+10FFFF,包括
U+0000 - U+FFFF,0号平面,基本多文种平面(Basic Multilingual Plane, BMP),定义多数语言的字符,包括ASCII字符、中日韩文字符等U+D800 - U+DBFF,保留作为UTF-16的高半区,High-half zone of UTF-16U+DC00 - U+DFFF,保留作为UTF-16的低半区,Low-half zone of UTF-16
U+10000 - U+1FFFF,1号平面,多文种补充平面(Supplementary Multilingual Plane, SMP),又称第一辅助平面,主要定义现在已不使用的古文字、音符、图形等,例如楔形文字、表情符号、扑克牌符号等U+20000 - U+2FFFF,2号平面,表意文字补充平面(Supplementary Ideographic Plane, SIP),又称第二辅助平面,整个平面定义的都是一些罕用的汉字或地区的方言用字U+30000 - U+3FFFF,3号平面,表意文字第三平面(Tertiary Ideographic Plane, TIP),尚未使用,但计划用于定义甲骨文、金文、小篆、中国战国时期文字等U+40000 - U+DFFFF,4到13号平面,尚未使用U+E0000 - U+EFFFF,14号平面,特别用途补充平面(Supplementary Special-purpose Plane, SSP),定义“语言编码标签”和“字形变换选取器”U+F0000 - U+FFFFF,15号平面,保留作为私人使用区A(Private Use Area-A, PUA-A)U+100000 - U+10FFFF,16号平面,保留作为私人使用区B(Private Use Area-B, PUA-B)
Unicode是一个符号集,仅规定了每个字符的二进制编码,例如英文使用7bit编码,中文’啊’的编码是U+554a,使用15bit编码,至少两个字节,其他字符可能使用更多字节;至于计算机如何理解,例如如何判断下一字节是一个英文字母还是一个中文字符的高位字节,Unicode并未定义;具体实现由不同的字符编码方式定义
Unicode有小端(little ending)和有大端(Big ending)记录两种方式,例如中文’啊’编码U+554a为大端序(Unicode Big Encoding),U+4a55为小端序(Unicode)
UTF-8
一种基于Unicode的可变长度编码,可以用于表示Unicode中所有字符;utf-8编码使用1到6个字节编码一个字符;尽管如此,规范规定只能使用Unicode已定义的区域,即U+0000到U+10FFFF,因此最多使用4个字节,其中
- 128个US-ASCII字符使用一个字节编码(U+0000到U+007F),兼容ASCII编码
- 带符号的拉丁字母、希腊字母等使用两个字节(U+0080到U+07FF)
- 其他BMP字符使用三个字节(U+0800到U+FFFF),例如中文
- 剩余字符使用四到六个字节
utf-8编码也是一种前缀码,编码规则
- 1个字节的符号,字节最高位总是0,同于ASCII
- n个字节(
n>1)的符号,最高位字节的高位为n个1,第n+1位为0,其他字节最高两位为10,剩下的位用于存储字符编码
例如中文’啊’,unicode为101010101001010,utf-8编码需要3字节存储,因此最高位字节以1110开头,其他字节以10开头,存储为11100101 10010101 10001010,十六进制表示E5 95 8A
utf-8无字节序,若存在BOM(EF BB BF)作用仅为识别文本编码为utf-8
肯·汤普森和罗勃·派克共同开发了utf-8;IETF要求所有互联网协议都必须支持utf-8编码,IMC(互联网邮件联盟)建议所有电子邮件软件都支持utf-8
UTF-16, UTF-32
UTF(Unicode/UCS Transformation Format),把Unicode字符转换为某种格式的意思;最常用包括utf-8, utf-16, utf-32,都是变长编码,区别是utf-16以多个16bit码元(code unit)表示,utf-32以多个32bit码元表示
对于英文字母,utf-8编码占1个字节,utf-16占2个字节,utf-32占4个字节,因此utf-16, utf-32不兼容ASCII,utf-32基本是固定长度编码;好处是多数字符都以固定长度的字节存储,例如utf-16中编码BMP字符都使用2字节,节省空间,而且除去了utf-8编码的填充位,加速识别有效位
utf-16是最早的Unicode字符集编码方式,使用2bytes编码BMP,4bytes编码辅助平面字符;因为没有utf-8的填充位,需要其他策略用于区分BMP和辅助平面字符;辅助平面字符共占用16个平面,使用20位可以表示;Unicode在分配BMP编码时保留两段用作utf-16编码识别
U+D800 - U+DBFF,用于映射非BMP字符的高10bitU+DC00 - U+DFFF,用于映射非BMP字符的低10bit
利用公式
H = Math.floor((code - 0x10000) / 0x400) + 0xD800
L = (code - 0x10000) % 0x400 + 0xDC00
偏移2^16以除去第一平面占用的编码,然后取高低10位;例如字符U+105FFF高10位转化为U+DBD7,低10位转化为U+DFFF;解析时遇到编码在U+D800 - U+DBFF范围内的码点,例如U+DBD7,即可判断处理的是4bytes的辅助平面字符
utf-16, utf-32单个码元多字节,有字节序;使用FF和FE两个字节作为BOM(Byte Order Mark),其中FF FE为小端存储方式,例如FF FE 4A 55是以小端序存储的utf-16编码’啊’,FE FF为大端序,例如FE FF 55 4A是以大端序存储的utf-16编码’啊’,utf-32使用00 00 FE FF, FF FE 00 00